Best AI papers explained
https://anchor.fm/s/1026675f8/podcast/rssEpisode List

Beyond Semantic Manipulation: Token-Space Attacks on Reward Models
This research paper introduces TOMPA, a novel framework designed to expose critical vulnerabilities in reward models used for aligning artificial intelligence. Unlike traditional adversarial methods that rely on human-readable text, this approach performs automated optimization directly in token space to bypass semantic constraints. By eliminating the need for coherent natural language, the system discovers non-linguistic token patterns that achieve exceptionally high scores from top-tier evaluators. Despite being identified as superior to high-quality human references, these generated outputs consist of nonsensical gibberish and repetitive symbols. The study demonstrates that reward hacking extends beyond simple linguistic biases, revealing a structural flaw where models prioritize specific raw data sequences over actual meaning. Ultimately, the authors argue that current RLHF pipelines remain highly susceptible to exploitation through these nonsensical, length-dependent adversarial patterns.
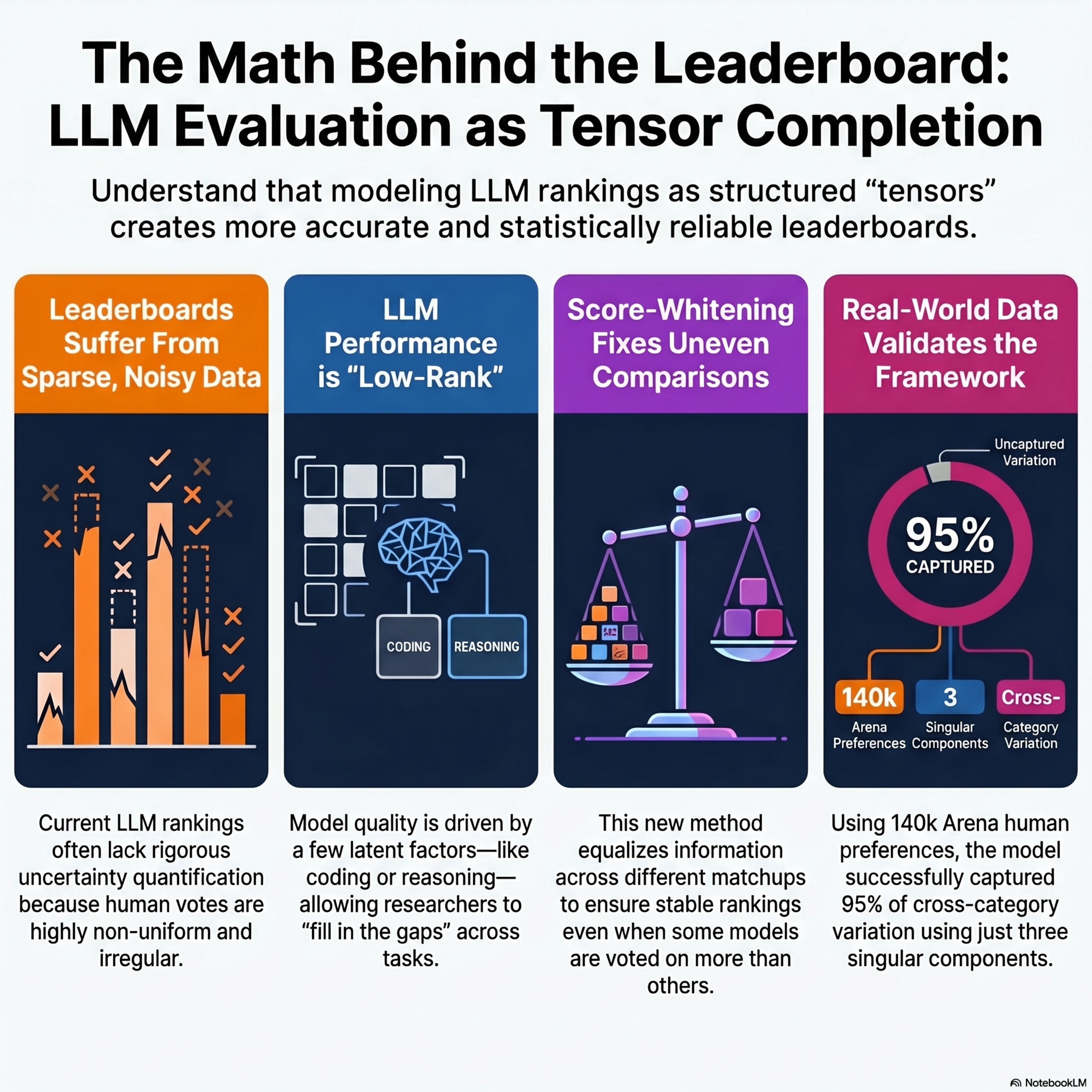
LLM Evaluation as Tensor Completion: Low-Rank Efficiency and Uncertainty Quantification
This paper introduces a rigorous statistical framework for evaluating Large Language Models (LLMs) by treating the problem as a low-rank tensor completion task. The researchers address the challenges of chatbot leaderboards, such as those on platforms like Chatbot Arena, which rely on noisy and sparse human preference data from pairwise model comparisons. By assuming that model performance across various tasks and contexts is driven by a small number of latent factors, the authors demonstrate how to "borrow strength" across categories to improve accuracy. They develop semiparametric efficiency bounds and a debiased one-step estimator to provide reliable confidence intervals and uncertainty quantification for model rankings. To resolve technical bottlenecks caused by non-uniform sampling, they introduce a score-whitening method that stabilizes inference across heterogeneous matchups. Their findings offer a principled approach to constructing more robust, statistically sound leaderboards for the rapidly evolving field of AI evaluation.
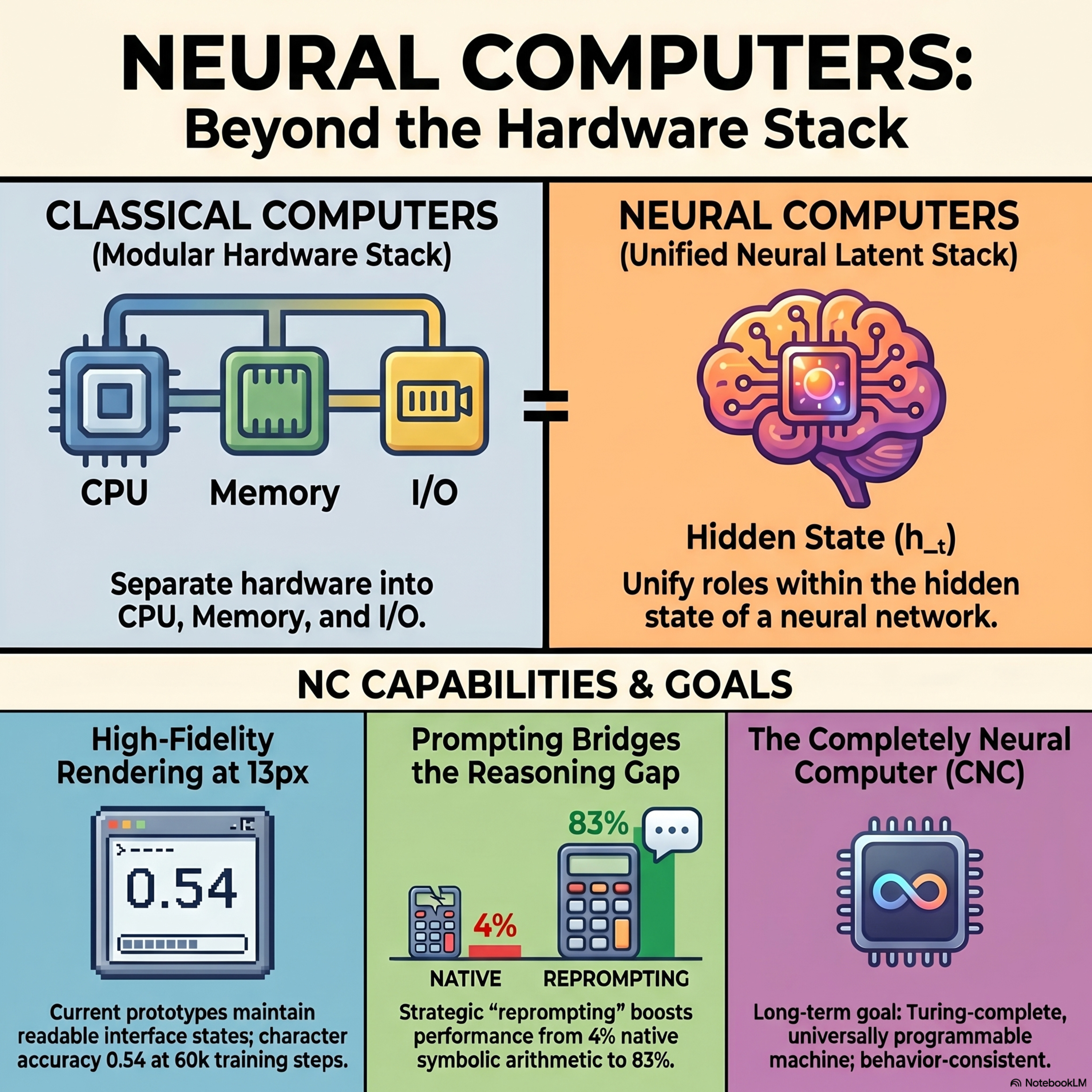
Neural Computers
Researchers have introduced Neural Computers (NCs), a transformative computing paradigm that merges memory, processing, and input/output into a single learned runtime state. Unlike traditional hardware that executes rigid code, these systems use neural networks to internalize the functions of a running computer. Current prototypes utilize video models to simulate interactive command-line and desktop environments based on user instructions and actions. While these early versions excel at visual rendering and short-term interface control, they still struggle with complex symbolic reasoning and long-term stability. The ultimate vision is the Completely Neural Computer (CNC), a general-purpose machine capable of durable capability reuse and explicit reprogramming. By shifting executable state from external software to the model's own latent dynamics, this approach seeks to move beyond the limitations of current AI agents and world models.
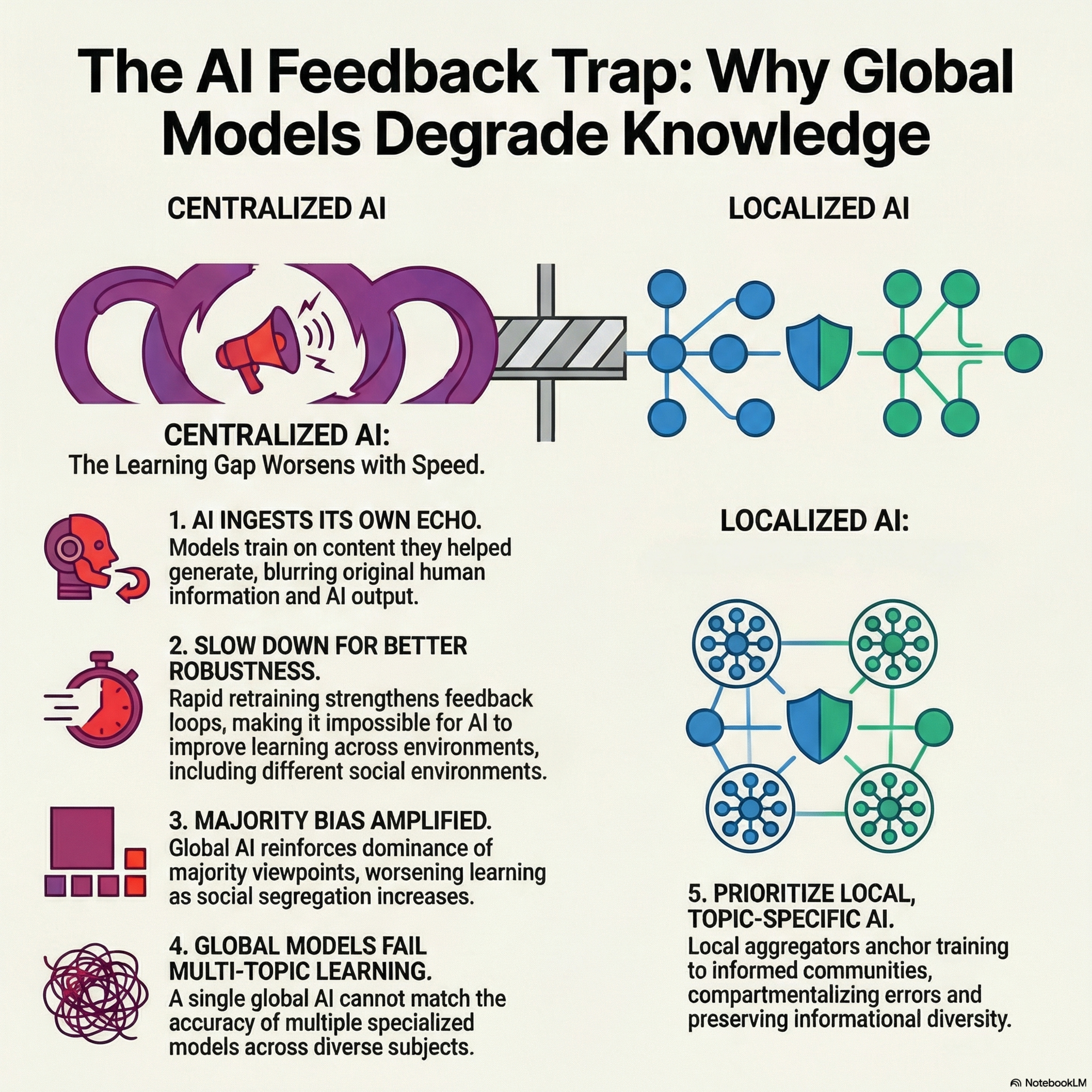
How AI Aggregation Affects Knowledge
This research examines how generative AI systems impact collective knowledge by creating feedback loops where AI outputs become future training data. Utilizing an expanded DeGroot model of social learning, the study demonstrates that when AI aggregators update too rapidly, they amplify existing social biases and segregation rather than correcting them. This phenomenon leads to a "learning gap," where long-run public beliefs deviate significantly from the truth, particularly when majority viewpoints are overrepresented in training data. The authors highlight a critical robustness tradeoff, showing that fast-learning global models often produce fragile and inaccurate social consensuses across diverse environments. Conversely, the text suggests that local, topic-specific aggregators are more effective at preserving informational diversity and improving long-term accuracy. Ultimately, the paper argues that centralized AI architectures inherently struggle with distributional tradeoffs, whereas modular systems can better compartmentalize feedback to protect the integrity of human knowledge.
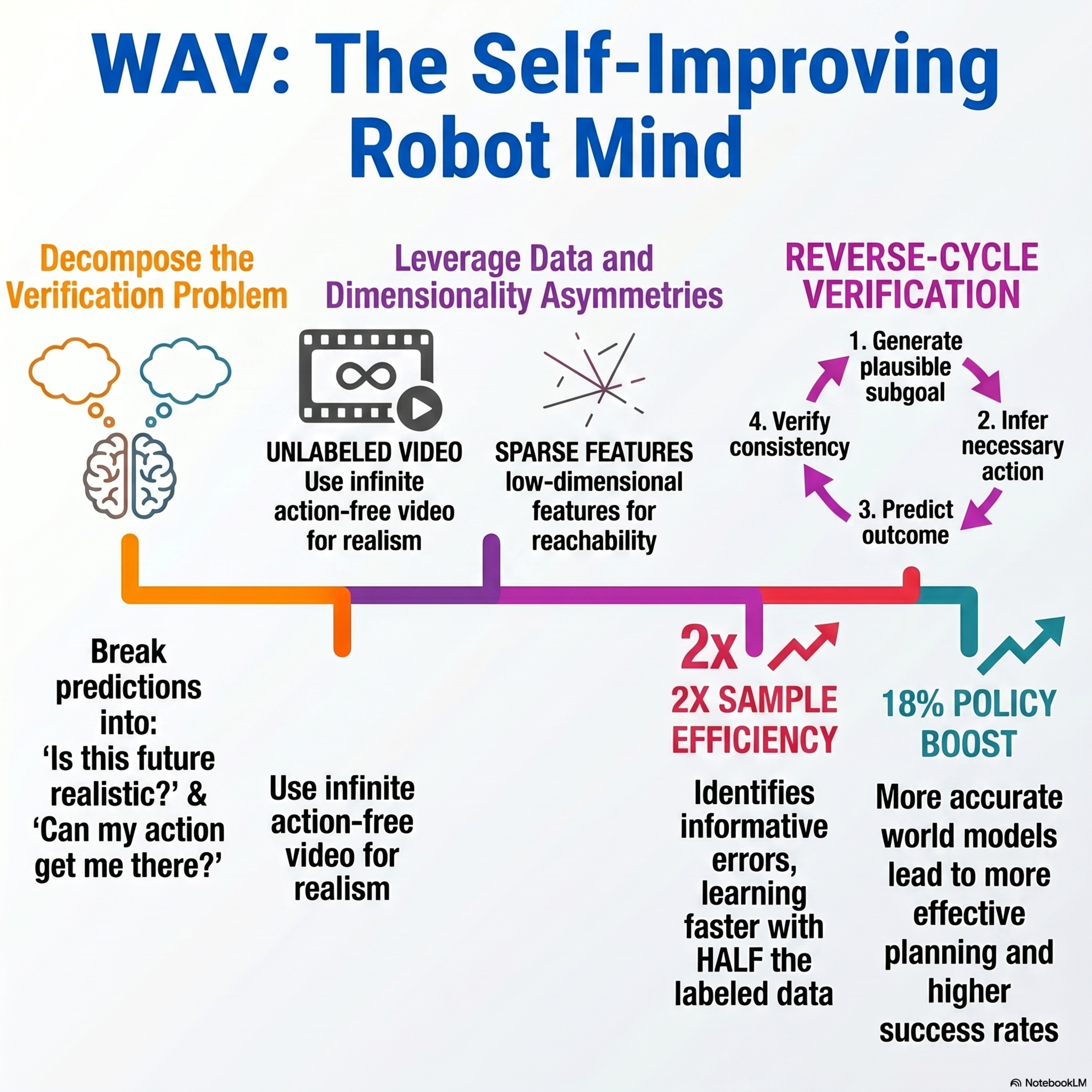
World Action Verifier: Self-Improving World Models via Forward-Inverse Asymmetry
We discuss World Action Verifier (WAV), a novel framework designed to enhance the reliability and efficiency of action-conditioned world models in robotics. The authors address the difficulty of training models to follow actions accurately, especially when labeled interaction data is scarce. By exploiting asymmetries between forward and inverse dynamics, WAV decomposes the prediction process into state plausibility and action reachability. The system utilizes a subgoal generator trained on abundant action-free video data and a sparse inverse model to verify if predicted transitions match intended actions. Theoretical analysis and experiments across nine tasks demonstrate that this approach identifies prediction errors more effectively than standard methods. Consequently, WAV doubles sample efficiency and improves the performance of downstream robotic policies by 18%.
You may also like
Get this podcast on your phone, Free


Create Your Podcast In Minutes
- Full-featured podcast site
- Unlimited storage and bandwidth
- Comprehensive podcast stats
- Distribute to Apple Podcasts, Spotify, and more
- Make money with your podcast
